24년 4월 21일 포스팅에 사용한 USD/KRW 환율 추이 차트를 그리는 법을 포스팅하려고 한다.
2024.04.21 - [Economy/Other] - 2024년 4월 16일, 장중 환율 1400원
2024년 4월 16일, 장중 환율 1400원
원/달러 환율이 24년 4월 16일 장중 1400원을 찍고 내려왔다. 1400원을 넘었던 적은 1997년 이후 총 3번 있었는데, 이번에 1400원을 찍어 총 4번을 기록했다. 4월 16일 왜 1400원을 터치했는지, 이 전 3건은
beer-pepperoni.tistory.com
목차
1. 데이터 다운 받기
2. 데이터 전처리
1. 데이터 다운 받기
우선 환율 데이터가 필요하다.
환율 데이터는 인베스팅이라는 사이트에서 받을 수 있다.
USD KRW 차트 - Investing.com
무료 실시간 스트리밍 USD KRW 차트에 즉시 접속할 수 있습니다. 이 고유한 미국 달러 원 차트를 통해 이 쌍의 동작을 명확하게 확인해 보세요.
kr.investing.com
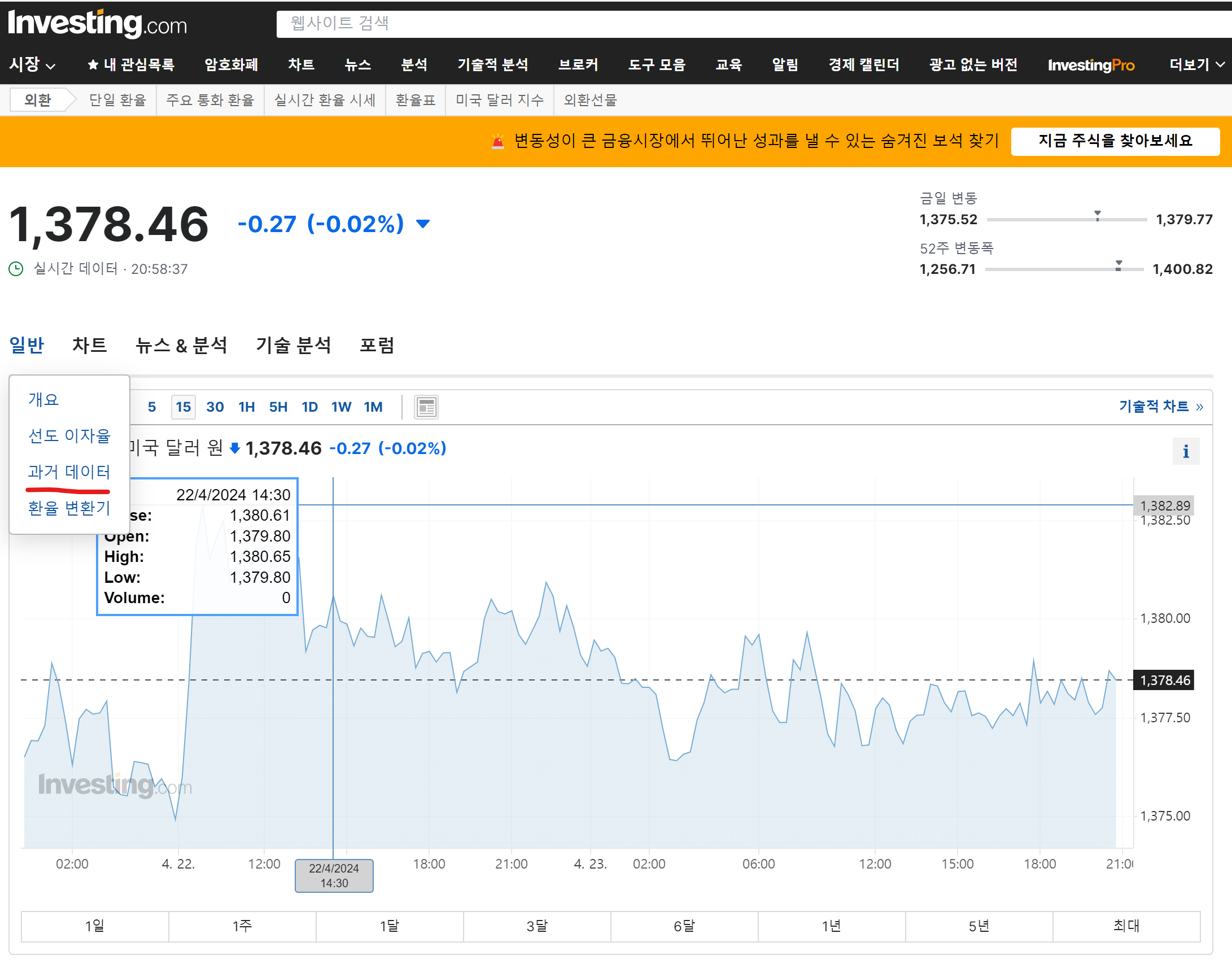
위 사이트에서 일반 - 과거 데이터에 들어가면
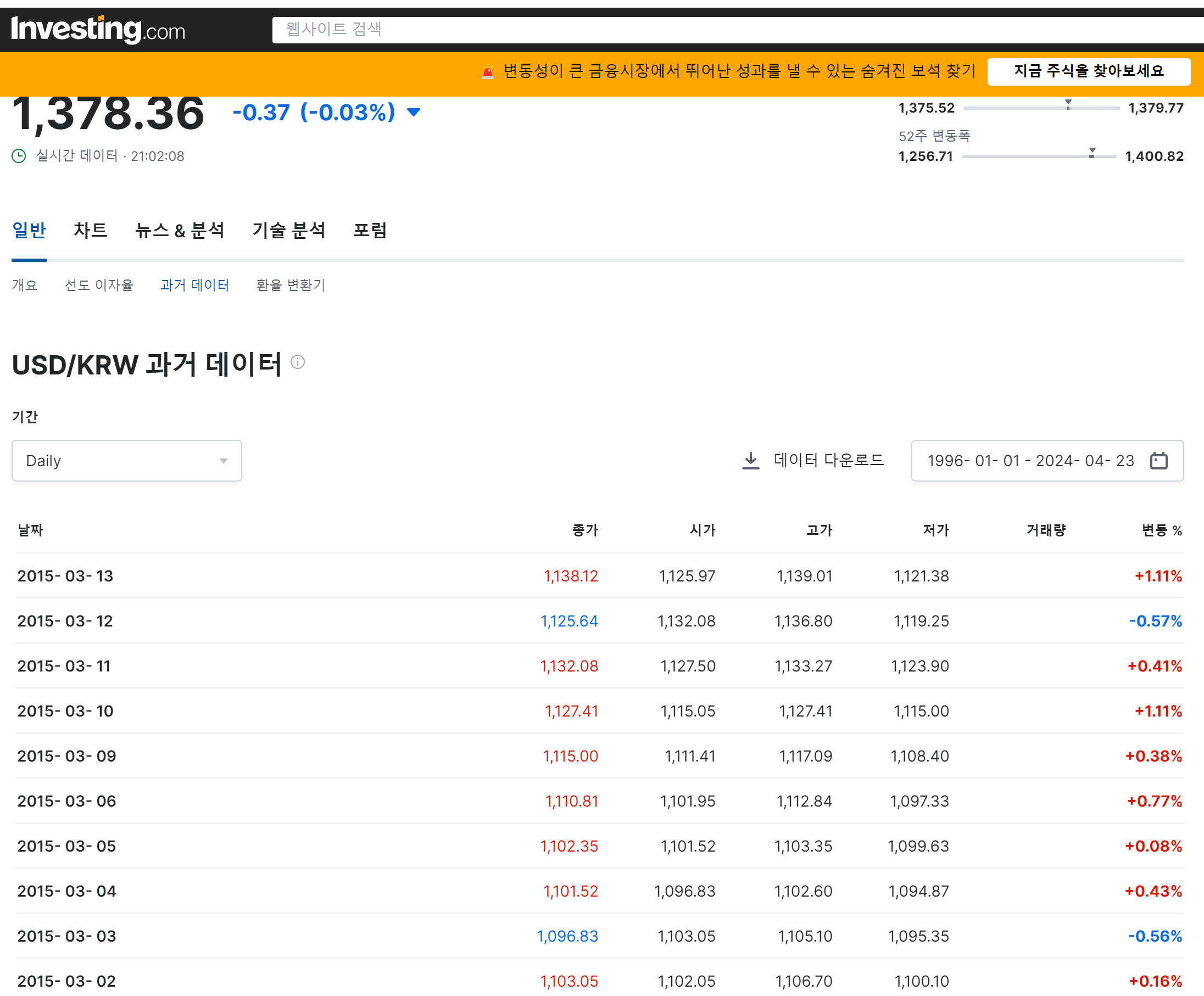
아래 화면이 나온다. 여기서 날짜를 1996년 1월 1일부터 오늘까지 날짜를 지정하면,
아래와 같이 2015년 3월 13일 데이터까지 검색이 된다.
일단 날짜 지하는 칸 옆에 데이터 다운로드를 누르면. csv 파일 형식으로 다운이 된다.
이후 날짜도 지정 후 다운 받으면 된다.
위 내용까지 잘 따라왔다면 아래와 같이 두 개의 .csv 파일이 생겼을 거다.
우린 이걸 가지고 전처리를 해보겠다.

2. 데이터 전처리
구글의 코랩으로 진행하겠다.
구글 메인화면에서 우측 상단에 점 9개 표시의 버튼을 누른 후 드라이브를 찾는다.


드라이브에 들어와 폴더를 하나 만들고
그 안에 다운 받은 데이터를 업로드한 후 편의를 위해 data_1, data_2로 파일명을 바꾼다.
data_1이 처음 다운 받았던 데이터이고, (1996.01.01~2015.03.13)
data_2가 그다음에 받았던 데이터이다.(2015.03.14~2024.04.23)
그리고 빈 곳을 우클릭 후 Google Colaboratory 파일을 하나 만들어 준다.
아래와 같은 창이 열릴 것이다.
여기서 파이썬 코딩을 할 예정이다.
우선 데이터 전처리를 위해
데이터를 불러오겠다. 그러기 위해 코랩 환경에서 구글 드라이브 마운트를 해야 한다.
아래 코드를 입력 후 코드 작성 칸 왼쪽의 화살표를 누르면 구글 드라이브가 마운트 된다.
팝업 창이 뜰 텐데 잘 읽어보고 연결하길 바란다.
from google.colab import drive
drive.mount('/content/drive')

마운트가 성공적으로 됐다.
그럼 왼쪽에 파일 버튼을 누르면 폴더가 나올 텐데 아래 경로를 따라 데이터 파일을 찾아야 한다.
drive - Mydrive - 생성한 폴더 - 저장한 데이터 파일
나는 drive - Mydrive - Python - Blog - 포스팅 날짜, 명 - 데이터 파일
경로로 저장해서 아래와 같이 나온다.
여기까지 따라왔으면 이제 코랩에서 파이썬을 이용해 데이터 파일을 불러오겠다.
먼저 패키지 선언을 해주겠다.
import pandas as pd
이 코드도 마찬가지로 작성 후 왼쪽의 화살표 버튼을 눌러주면 된다.
그럼 pandas 패키지가 선언됐고 앞으로 pd라는 단어로 불러올 수 있다.
우선 data_1의 데이터를 데이터 프레임에 저장하겠다.
아까 찾은 데이터 파일을 우클릭하면 경로를 복사할 수 있다.
아래 코드에 df1 = pd.read_csv('경로 붙여 넣기')를 입력해 주면 된다.
df1이라는 데이터 프레임을 만들어 csv 파일을 데이터 프레임 안에 저장한다는 말이다.
df1 = pd.read_csv('/content/drive/MyDrive/Python/Blog/24.04.23_파이썬으로 선형 차트 만들기/data_1.csv')
잘 불러왔는지 확인해 보겠다.
아래 코드로 확인 가능하다.
위에서 5개의 data만 불러오겠다는 말이다.
위에서 5개의 data만 불러오는 이유는 데이터를 다루다 보면,
엄청나게 많은 양의 데이터를 다루게 되는데,
많은 양의 데이터를 코드가 잘 작성되었는지 확인하기 위해 불러오기엔 비효율적이기 때문이다.
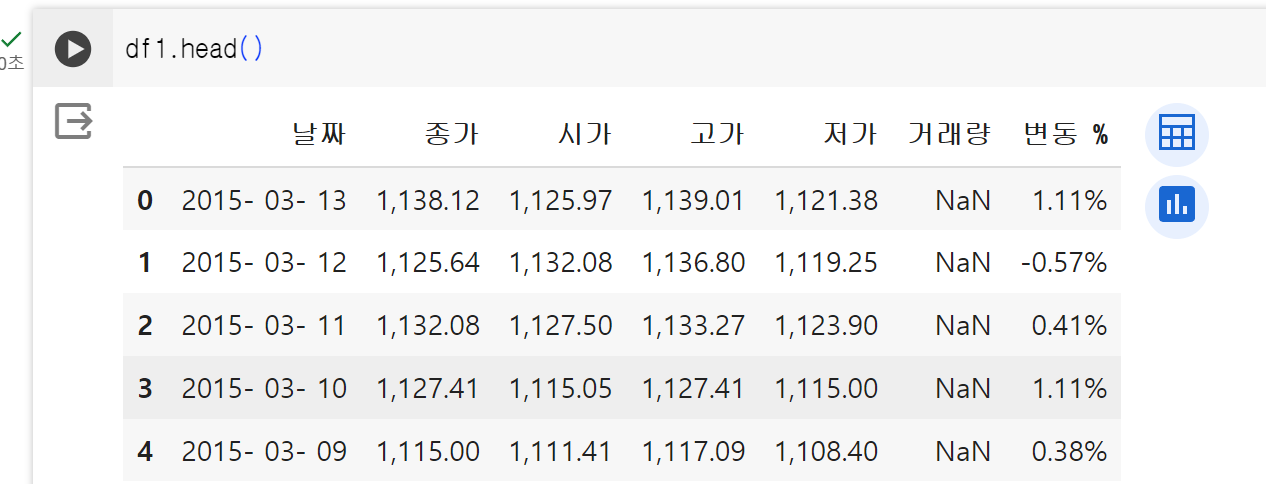
df1.head()
아래와 같이 나오면 성공이다.
2번 데이터도 불러오겠다.
df2 = pd.read_csv('/content/drive/MyDrive/Python/Blog/24.04.23_파이썬으로 선형 차트 만들기/data_2.csv')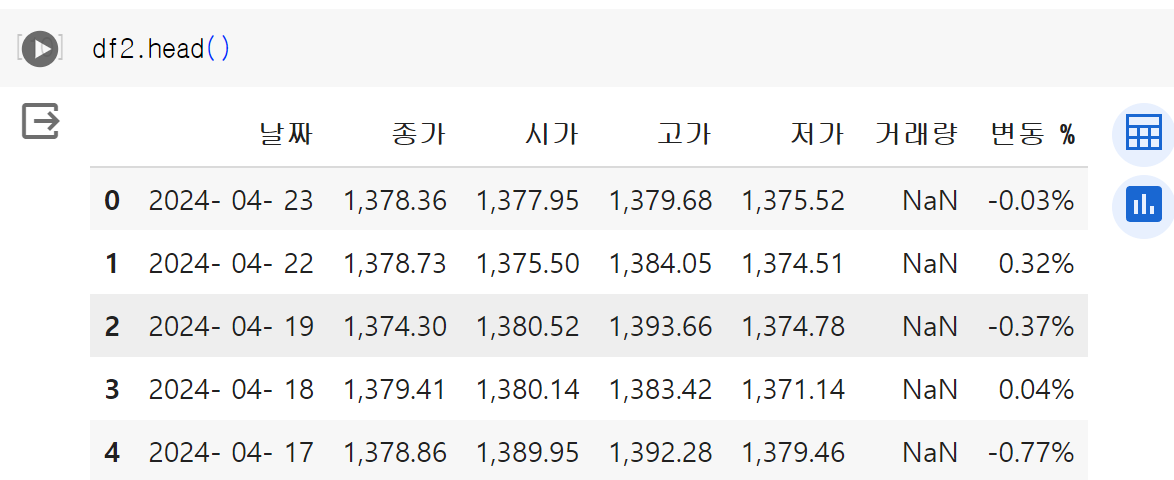
둘 다 늦은 날짜가 위에 있는 모습이다.
빠른 날짜가 위에 오도록 바꾸는 게 편하다.
방법은 아래와 같다.
우선, df1의 날짜 열을 datetime 객체로 변환한다.
df1['날짜'] = pd.to_datetime(df1['날짜'])
그다음 df1에 df1을 날짜 기준으로 오름차순 한 데이터를 저장한다.
df1 = df1.sort_values(by='날짜', ascending=True)
그 다음 확인해 보면 잘 된 걸 확인할 수 있다.
df1.head()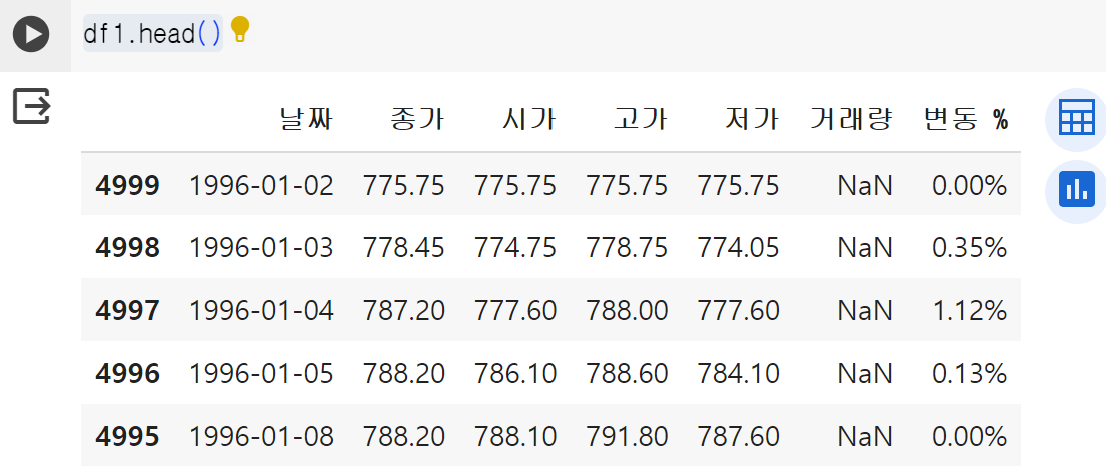
df2도 동일하게 진행하길 바란다.
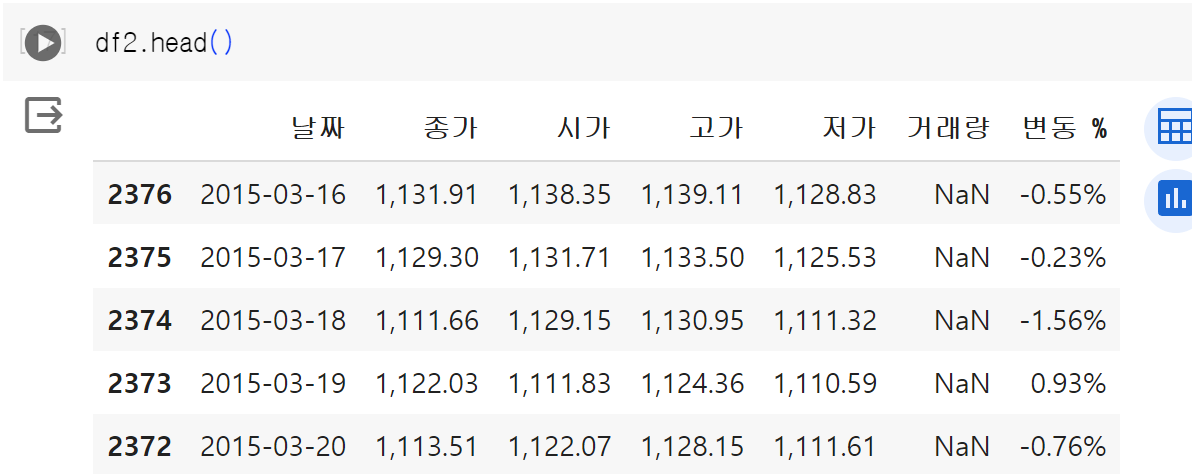
하나의 차트를 만들기 위해선 데이터 프레임이 하나여야 하는데
지금은 데이터가 하나인 상황이다.
그래서 데이터를 합쳐보겠다.
데이터를 합치는 방법은 여러 가지지만,
이번 포스팅에서 필요한 방법은 df2의 데이터를 df1 아래에 합치는 방법이 필요하다.
df 데이터 프레임에 concat 함수를 써서 df1 아래 df2의 데이터를 합칠 수 있다.
df = pd.concat([위에 올 데이터 프레임, 아래 붙일 데이터 프레임], ignore_index=True) 형식이다.
df = pd.concat([df1, df2], ignore_index=True)
여기서 ignore_index=True은 인덱스가 겹치지 않고 df1의 인덱스를 이어서 df2의 인덱스를 시작하게 해주는 옵션이다.
인덱스란 아래에 빨간 부분을 말한다.
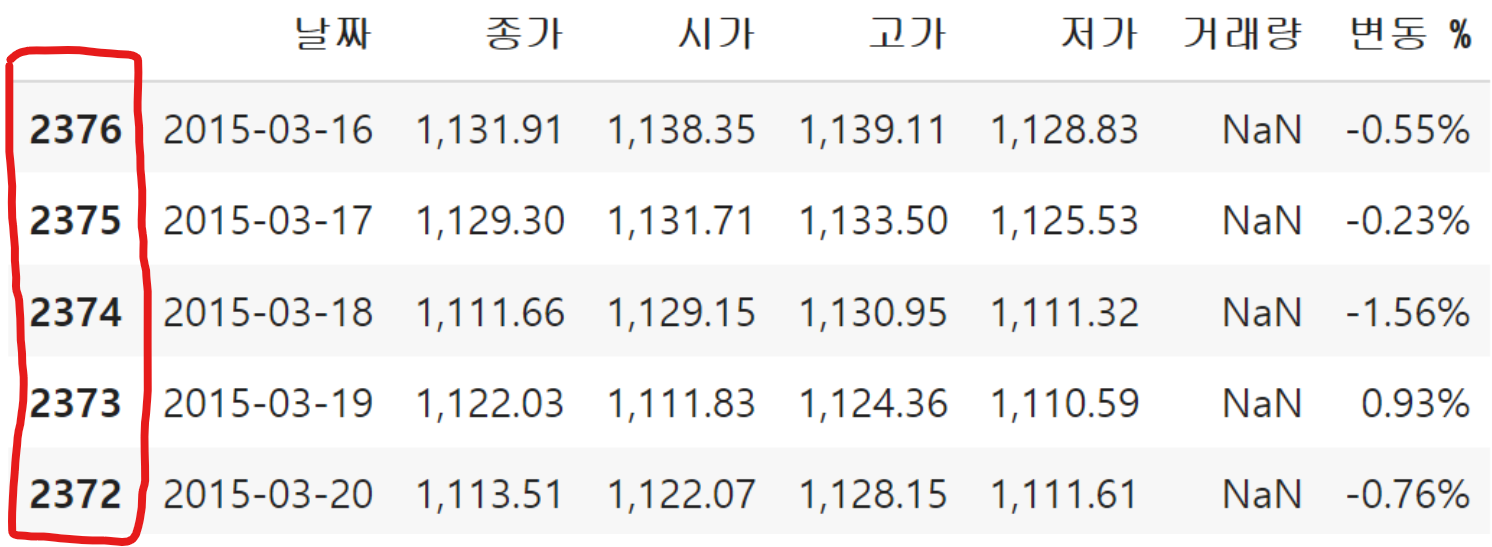
이제 데이터가 잘 붙었는지 확인해 보겠다.
우선 df의 윗부분 데이터를 확인해 보겠다.
df.head()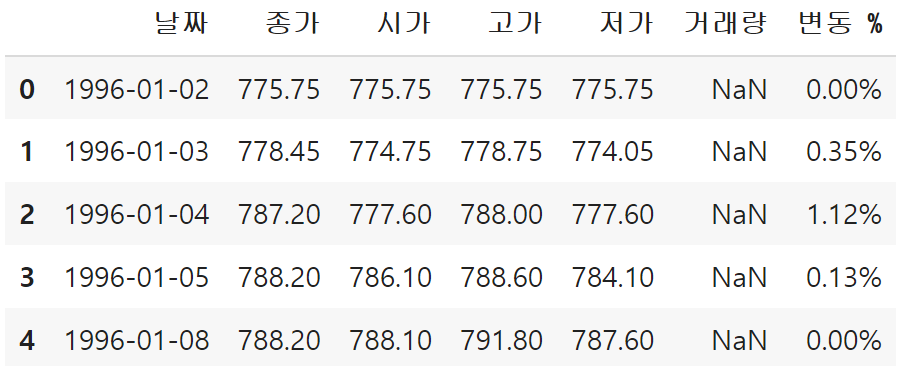
df1의 데이터가 윗부분으로 잘 들어갔다.
아랫부분을 확인하는 방법은 tail() 함수를 이용하는 방법이다.
df.tail()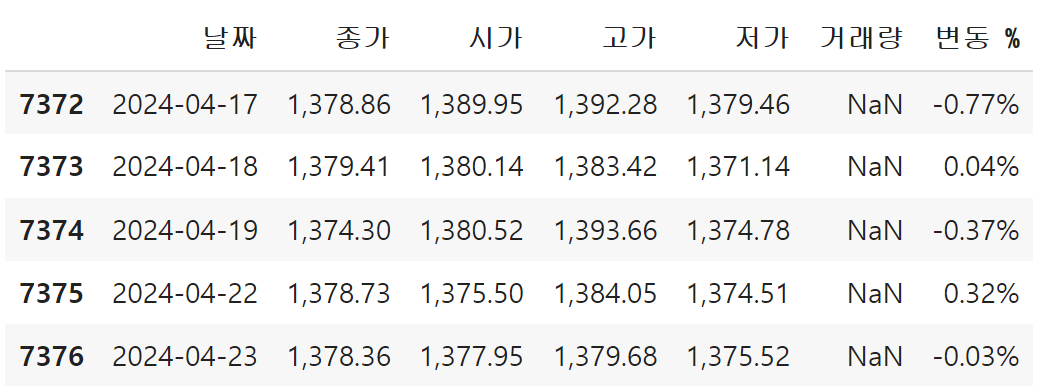
오늘 날짜인 24년 4월 23일 데이터까지 잘 들어간 모습이다.
df를 한 번에 확인하려면 아래와 같은 방법으로 확인하면 된다.
df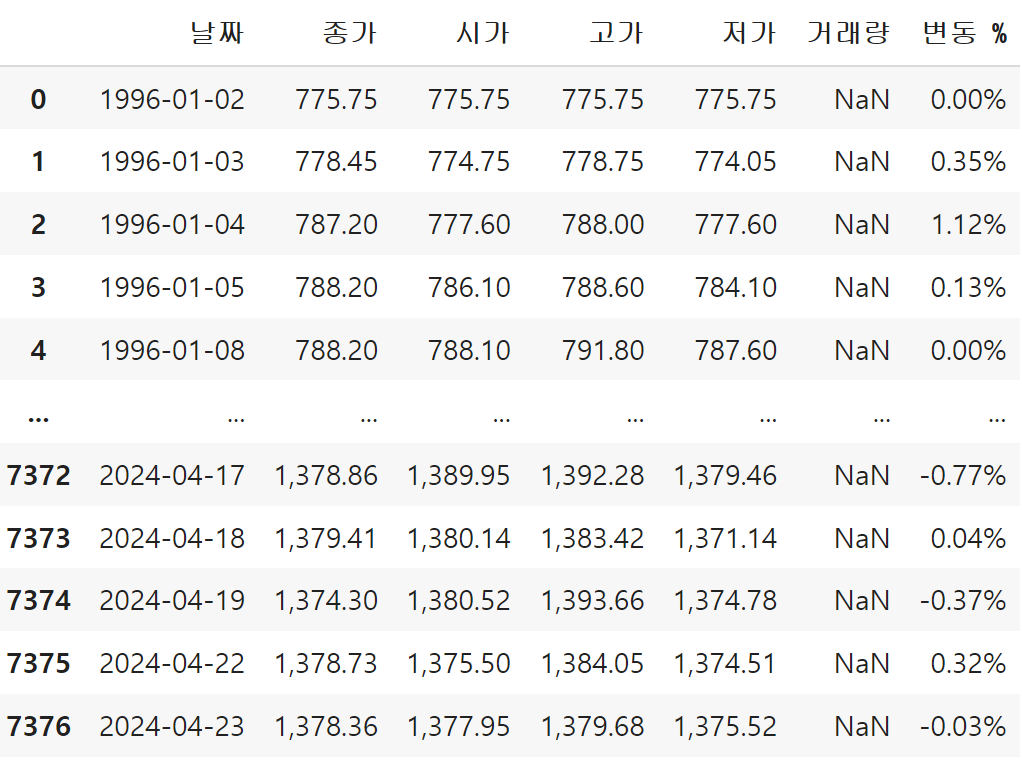
알아서 중간 부분이 생략돼서 나온다.
오늘은 데이터를 다운받아 불러오고 전처리 초반 부분까지 해보았다.
다음 포스팅에선 전처리 후반부와 차트 그리는 방법을 다루겠다.
'Computer > Python' 카테고리의 다른 글
| 파이썬 데이터 전처리, 차트 작성 (0) | 2024.05.06 |
|---|
